这篇博客主要介绍下CVPR 2016 YOLO v1算法(CVPR2016的文章)。YOLO是比较流行的object detection算法,速度快且结构简单,这里算法部分介绍的是YOLO的第一个版本,而现在YOLO的官网上已经有YOLO v2和v3的实现了。
论文名称:You only look once unified real-time object detection
论文链接:https://www.cv-foundation.org/openaccess/content_cvpr_2016/html/Redmon_You_Only_Look_CVPR_2016_paper.html
YOLO v1 算法内容
作者在YOLO算法中把物体检测(object detection)问题处理成回归问题,用一个卷积神经网络结构就可以从输入图像直接预测bounding box和类别概率。
YOLO算法的优点
- YOLO的速度非常快。在Titan X GPU上的速度是45 fps(frames per second),加速版的YOLO差不多是150fps。
- YOLO是基于图像的全局信息进行预测的。这一点和基于sliding window以及region proposal等检测算法不一样。与Fast R-CNN相比,YOLO在误检测(将背景检测为物体)方面的错误率能降低一半多。
- YOLO可以学到物体的generalizable representations。可以理解为泛化能力强。
- 准确率高,有实验证明。
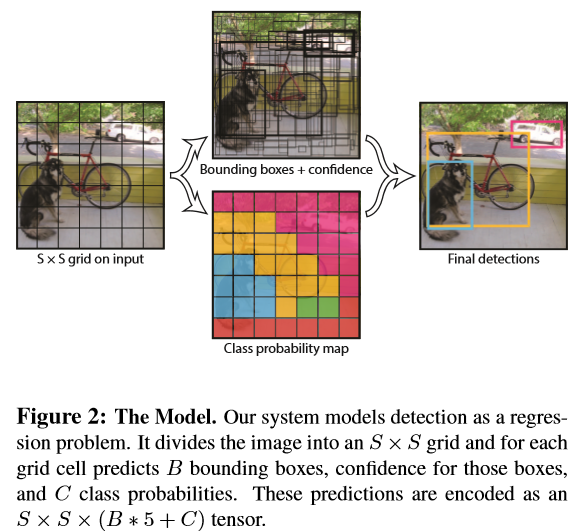
算法结构图如下图1:结构上主要的特点就是 unified detection(统一检测),不再是原来许多步骤组成的物体检测,这使得模型的运行速度快,可以直接学习图像的全局信息,且可以end-to-end训练。
首先把输入图像划分成S*S的格子,然后对每个格子都预测B个bounding boxes,每个bounding box都包含5个预测值:x,y,w,h和confidence。x,y就是bounding box的中心坐标,与grid cell对齐(即相对于当前grid cell的偏移值),使得范围变成0到1;w和h进行归一化(分别除以图像的w和h,这样最后的w和h就在0到1范围)。
另外每个格子都预测C个假定类别的概率。在本文中作者取S=7,B=2,C=20(因为PASCAL VOC有20个类别),所以最后有7730个tensor,应注意每个bounding box都对应一个confidence score。如下图2。
这里confidence的计算公式如下:
这里如果grid cell里面没有object,则$Pr(object) = 0$ , 如果grid cell里面有object,则$Pr(object) = 1$ 。因此如果grid cell里面没有object,confidence就是0,如果有,则confidence score等于预测的box和ground truth的IOU值,见上面公式。
那么如何判断一个grid cell中是否包含object呢?答案是:如果一个object的ground truth的中心点坐标在一个grid cell中,那么这个grid cell就是包含这个object,也就是说这个object的预测就由该grid cell负责。
除此之外,不管B boxes有几个,每个grid cell都固定预测C个类别概率,表示一个grid cell在包含object的条件下属于某个类别的概率。
在测试的时候,我们将在grid cell在有object的条件下的条件概率,和这个grid cell中所有box的置信度confidence predictions相乘,得到每个box中每一类的置信分数。公式如下:
这个分数计算保证了每个box中物体类别的预测概率和box本身是否贴合物体两方面的表现。
这个乘法具体实现如下图:每个bounding box的confidence和每个类别的score相乘,得到每个bounding box属于哪一类的confidence score。
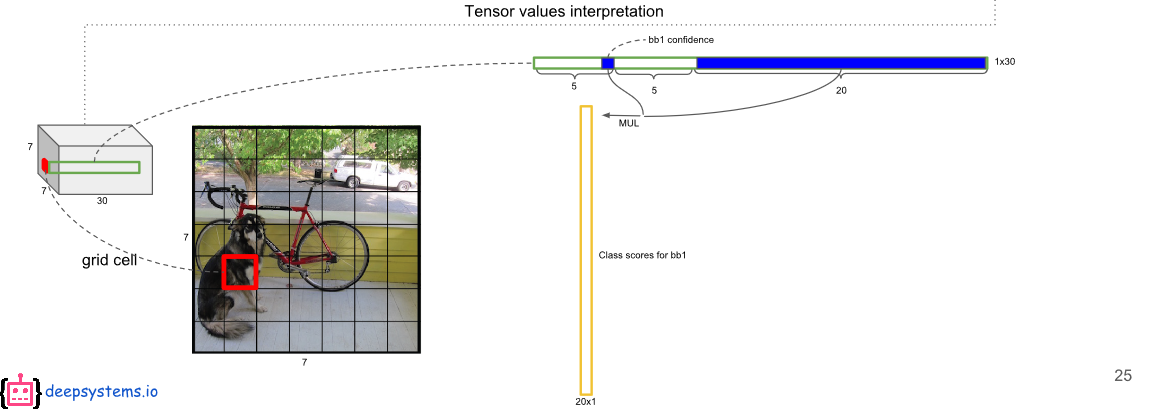
即得到每个bounding box属于哪一类的confidence score。也就是说最后会得到20(772)=2098的score矩阵,括号里面是bounding box的数量,20代表类别。接下来的操作都是20个类别轮流进行:在某个类别中(即矩阵的某一行),将得分少于阈值(0.2)的设置为0,然后再按得分从高到低排序。最后再用NMS算法去掉重复率较大的bounding box(NMS:针对某一类别,选择得分最大的bounding box,然后计算它和其它bounding box的IOU值,如果IOU大于0.5,说明重复率较大,该得分设为0,如果不大于0.5,则不改;这样一轮后,再选择剩下的score里面最大的那个bounding box,然后计算该bounding box和其它bounding box的IOU,重复以上过程直到最后)。最后每个bounding box的20个score取最大的score,如果这个score大于0,那么这个bounding box就是这个socre对应的类别(矩阵的行),如果小于0,说明这个bounding box里面没有物体,跳过即可。具体细节参考最后的参考资料1。
训练用的网络方面受GoogLeNet的启发,但不像googlenet一样使用inception model,仅叠加11的降维层和33的卷积层,卷积层主要用来提取特征,全连接层主要用来预测类别概率和坐标。最后的输出是7730,这个30前面也解释过了,77是grid cell的数量。中间特征提取可能不同,重点在于最后一层的输出是77*30。网络结构如下图所示: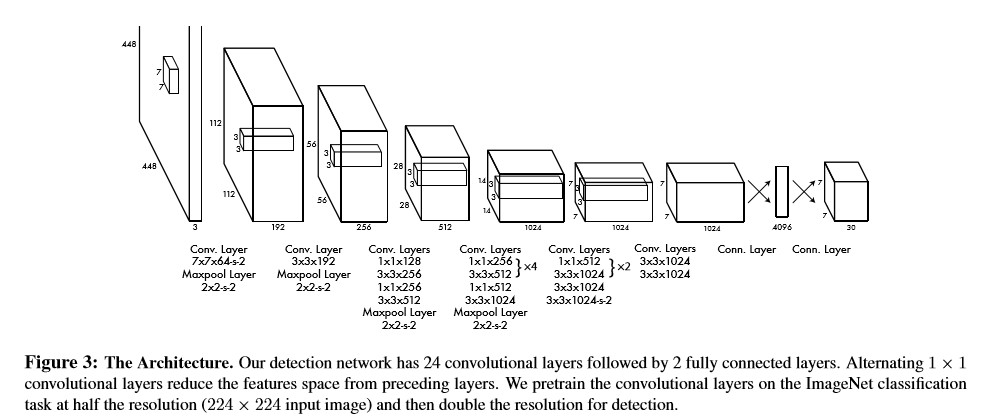
训练策略
该论文的训练策略,总体给人的感觉:比较复杂,技巧性比较强。可以看得出作者为了提升性能花了不少功夫。
- 首先利用 ImageNet 的数据集 Pretrain 卷积层。使用上述网络中的前 20 个卷积层,外加一个全连接层,作为 Pretrain 的网络,训练大约一周的时间,使得在 ImageNet 2012 的验证数据集 Top-5 的准确度达到 88%,这个结果跟 GoogleNet 的效果相当。
- 将 Pretrain 的结果应用到 Detection 中,将剩下的 4 个卷积层及 2 个全连接成加入到 Pretrain 的网络中。同时为了获取更精细化的结果,将输入图像的分辨率由 224224 提升到 448448。
- 将所有的预测结果都归一化到 0~1, 使用 Leaky RELU 作为激活函数。
- 对比 localization error 和 classification error,加大 localization 的权重
- 在 Pascal VOC 2007 和 2012 上训练 135 个 epochs, Batchsize 设置为 64, Momentum 为 0.9, Decay 为 0.0005.
- 在第一个 epoch 中 学习率是逐渐从 $10^{-3}$ 增大到$10^{-2}$ ,然后保持学习率为$10^{-2}$,一直训练到 75个 epochs,然后学习率为$10^{-3}$ ,训练 30 个 epochs, 最后学习率为$10^{-4}$ 训练 30 个 epochs。
- 为了防止过拟合,在第一个全连接层后面接了一个 ratio=0.5 的 Dropout 层。并且对原始图像做了一些随机采样和缩放,甚至对调节图像的在 HSV 空间的饱和度。
- 训练过程中,小的 Box 对位置回归错误比大的 Box 更加敏感,由于坐标都已经归一化到 0~1,之间,作者使用了一个 trick,不是直接使用平方,而是使用它们的平方根。
损失函数方面
作者采用sum-squared error的方式把localization error(bounding box的坐标误差)和classificaton error整合在一起。但是如果二者的权值一致,容易导致模型不稳定,训练发散。因为很多grid cell是不包含物体的,这样的话很多grid cell的confidence score为0。所以采用设置不同权重方式来解决,一方面提高localization error的权重,另一方面降低没有object的box的confidence loss权值,loss权重分别是5和0.5。而对于包含object的box的confidence loss权值还是原来的1。详见下面的原文解释和loos function函数(这里latex写起来太长了,就直接截图了)。
在loss function中,前面两行表示localization error(即坐标误差),第一行是box中心坐标(x,y)的预测,第二行为宽和高的预测。这里注意用宽和高的开根号代替原来的宽和高,这样做主要为了增加模型的稳定性,因为相同的宽和高误差对于小的目标精度影响比大的目标要大。举个例子,原来w=10,h=20,预测出来w=8,h=22,跟原来w=3,h=5,预测出来w1,h=7相比,其实前者的误差要比后者小,但是如果不加开根号,那么损失都是一样:4+4=8,但是加上根号后,变成0.15和0.7(这一段是从这篇博客中看来得https://blog.csdn.net/u014380165/article/details/72616238)。
第三、四行表示bounding box的confidence损失,就像前面所说的,分成grid cell包含与不包含object两种情况。这里注意下因为每个grid cell包含两个bounding box,所以只有当ground truth 和该网格中的某个bounding box的IOU值最大的时候,才计算这项。
第五行表示预测类别的误差,注意前面的系数只有在grid cell包含object的时候才为1。
所以具体实现的时候是什么样的过程呢?
训练的时候:输入N个图像,每个图像包含M个objec,每个object包含4个坐标(x,y,w,h)和1个label。然后通过网络得到7730大小的三维矩阵。每个130的向量前5个元素表示第一个bounding box的4个坐标和1个confidence,第6到10元素表示第二个bounding box的4个坐标和1个confidence。最后20个表示这个grid cell所属类别。注意这30个都是预测的结果。然后就可以计算损失函数的第一、二 、五行。至于第二三行,confidence可以根据ground truth和预测的bounding box计算出的IOU和是否有object的0,1值相乘得到。真实的confidence是0或1值,即有object则为1,没有object则为0。 这样就能计算出loss function的值了。
测试的时候:输入一张图像,跑到网络的末端得到77*30的三维矩阵,这里虽然没有计算IOU,但是由训练好的权重已经直接计算出了bounding box的confidence。然后再跟预测的类别概率相乘就得到每个bounding box属于哪一类的概率。
YOLO算法的缺点
1、位置精确性差,对于小目标物体以及物体比较密集的也检测不好,比如一群小鸟。
2、YOLO虽然可以降低将背景检测为物体的概率,但同时导致召回率较低。
3、每个 grid 只预测一个 类别的 Bounding Boxes,而且最后只取置信度最大的那个 Box。这就导致如果多个不同物体(或者同类物体的不同实体)的中心落在同一个网格中,会造成漏检。
4、预测的 Box 对于尺度的变化比较敏感,在尺度上的泛化能力比较差。
在测试阶段,每张图像只预测 772 = 98 个 Box,所以速度非常快。在训练过程中,每个网格预测多个 Box,但是对于每个类别只预测一个结果,相对来说对类别的预测要求更高,得到的结果较为准确,该方法的主要错误来源于定位 (localization) 的错误。这也许是该方法对背景误判的错误率低的原因。
问题补充:
一个grid cell中是否有object怎么界定?
首先要明白grid cell的含义,以文中77为例,这个size其实就是对输入图像(假设是224224)不断提取特征然后sample得到的(5个pooling层缩小了32倍),然后就是把输入图像划分成7*7个grid cell,这样输入图像中的32个像素点就对应一个grid cell。回归正题,那么我们有每个object的标注信息,也就是知道每个object的中心点坐标在输入图像的哪个位置,那么不就相当于知道了每个object的中心点坐标属于哪个grid cell了吗,而只要object的中心点坐标落在哪个grid cell中,这个object就由哪个grid cell负责预测,也就是该grid cell包含这个object。另外由于一个grid cell会预测两个bounding box,实际上只有一个bounding box是用来预测属于该grid cell的object的,那么这两个bounding box到底哪个来预测呢?答案是:和该object的ground truth的IOU值最大的bounding box。
参考资料:
1、https://docs.google.com/presentation/d/1aeRvtKG21KHdD5lg6Hgyhx5rPq_ZOsGjG5rJ1HP7BbA/pub?start=false&loop=false&delayms=3000&slide=id.p
2、https://blog.csdn.net/u014380165/article/details/72616238